Introduction
En lisant le rapport Malt Tech Trends 2025 sur les compétences liées à l’intelligence artificielle les plus recherchées sur la plateforme on retrouve en première position : le RAG (Retrieval-Augmented Generation).
Dans cette article, nous définirons ce qu’on entend précisément par RAG et nous appliquerons une technique de RAG en Java grâce à Spring AI et une base de données vectorielle Postgres.
Qu’est-ce que le RAG ?
Les LLMs sont des modèles entraînés par machine Learning sur des data set qui proviennent d’internet et qui sont plus anciennes. Aujourd’hui les LLMs vont chercher de la donnée sur internet pour la comparée avec la donnée sur lesquelles ils ont été entrainés. C’est comme ça qu’on arrive à avoir un résultat à jour d’une réponse d’un LLM. Cependant, il arrive que le LLM « hallucine », c’est-à-dire qu’il donne une réponse hasardeuse voir totallement fausse. C’est pourquoi on fait du RAG, pour limiter les hallucinations des LLM notamment sur des données spécifiques (un data-set qu’on va lui fournir), par exemple des données d’entreprises, de la documentation, une banque d’image etc.
Les modèles de langage et leurs méthodes d’actualisation
Les LLMs (Large Language Models) sont des modèles d’intelligence artificielle entraînés par apprentissage automatique sur d’immenses jeux de données (ou data set en anglais) collectés principalement sur internet. Ces données d’entraînement ont une date de coupure, ce qui signifie qu’elles ne contiennent pas d’informations postérieures à cette date.
Pour obtenir des informations plus récentes, certains LLMs peuvent être équipés d’outils de recherche leur permettant d’interroger internet en temps réel. Lorsque vous posez une question, le modèle peut alors comparer ses connaissances pré-entraînées avec les informations fraîchement récupérées pour fournir une réponse actualisée. Cette capacité n’est cependant pas automatique – elle dépend de l’architecture du système et des outils mis à disposition du modèle.
Le défi des hallucinations
Un problème récurrent avec les LLMs est qu’ils peuvent « halluciner », c’est-à-dire générer des réponses plausibles en apparence mais factuellement incorrectes, voire totalement fausses. Ces erreurs peuvent survenir même lorsque le modèle a accès à des sources externes, car il peut mal interpréter ou mal synthétiser les informations trouvées.
Le RAG comme solution
C’est là qu’intervient le RAG. Cette technique permet de limiter les hallucinations en fournissant au LLM un accès contrôlé à des sources de données spécifiques et fiables. Au lieu de s’appuyer uniquement sur ses connaissances pré-entraînées ou sur des recherches web générales, le modèle peut puiser dans des bases de données ciblées comme la documentation d’entreprise, des manuels techniques, ou des collections d’images spécifiques. Cela améliore considérablement la fiabilité et la pertinence des réponses dans des domaines particuliers.
Comment ça marche ?
Imaginez le RAG comme un système de bibliothèque intelligente. Pour comprendre son fonctionnement, nous devons d’abord saisir le rôle central des bases de données vectorielles, qui constituent le cœur de cette architecture.
La transformation des données en langage mathématique
Les bases de données vectorielles stockent l’information sous forme de vecteurs numériques, ce qui peut sembler abstrait au premier abord. Pensez à ces vecteurs comme à des « empreintes digitales mathématiques » de vos données. Chaque phrase, chaque paragraphe de votre documentation est transformé en une série de nombres qui capture son sens sémantique. Cette représentation vectorielle permet au système de comprendre non seulement les mots exacts, mais aussi leur signification contextuelle.
Le processus de préparation des données
La création de cette bibliothèque vectorielle suit un processus méthodique appelé ETL (Extract, Transform, Load). Commençons par comprendre chaque étape. L’extraction consiste à récupérer le contenu depuis vos sources originales, qu’il s’agisse de documents PDF, de pages web, ou de bases de données internes. Ensuite vient une étape cruciale : le découpage en « chunks » ou segments. Cette fragmentation n’est pas aléatoire – elle vise à créer des morceaux d’information de taille optimale, ni trop petits pour perdre le contexte, ni trop grands pour diluer l’information pertinente.
La vectorisation de ces segments fait appel à des modèles d’embedding spécialisés. Ces modèles, souvent basés sur des architectures de transformeurs, excellent dans l’art de capturer les nuances sémantiques du langage. Ils transforment chaque chunk en un vecteur de plusieurs centaines, voire milliers de dimensions, créant ainsi une cartographie mathématique du sens.

Le processus de récupération et de génération
Une fois votre base vectorielle constituée, le système peut traiter les requêtes utilisateurs de manière sophistiquée. Lorsqu’un utilisateur pose une question, celle-ci est d’abord vectorisée en utilisant le même modèle d’embedding que celui utilisé pour la base de données. Cette cohérence est essentielle pour assurer une recherche de similarité efficace.
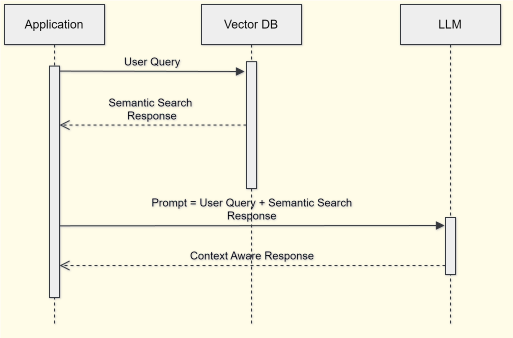
Le système recherche ensuite dans la base vectorielle les segments les plus pertinents en calculant la proximité sémantique entre le vecteur de la question et ceux stockés. Cette recherche par similarité est bien plus puissante qu’une simple recherche par mots-clés, car elle peut identifier des contenus conceptuellement liés même s’ils n’utilisent pas exactement les mêmes termes.
Enfin, l’étape de génération combine intelligemment la question originale avec les informations contextuelles récupérées. Cette combinaison est envoyée au LLM générateur, qui dispose ainsi d’un contexte riche et spécifique pour formuler sa réponse. Le modèle peut alors générer une réponse en langage naturel qui s’appuie sur vos données spécifiques plutôt que sur ses seules connaissances pré-entraînées.
Cette architecture garantit que les réponses restent ancrées dans vos données tout en bénéficiant des capacités de raisonnement et d’expression du modèle de langage.
Implémentation pratique : RAG avec Spring AI et PostgreSQL
Maintenant que nous avons compris les concepts théoriques du RAG, passons à la mise en pratique avec Spring AI et PostgreSQL. Cette section vous guidera pas à pas dans la création d’une application Java complète.
Prérequis et configuration de l’environnement
Avant de commencer l’implémentation, nous devons préparer notre environnement de développement. Cette étape est cruciale car elle détermine la facilité avec laquelle nous pourrons développer et tester notre solution RAG.
Configuration de PostgreSQL avec pgvector
PostgreSQL seul ne suffit pas pour notre cas d’usage. Nous avons besoin de l’extension pgvector qui transforme PostgreSQL en une base de données vectorielle performante. Cette extension ajoute le type de données VECTOR et les opérateurs de similarité nécessaires pour nos calculs sémantiques.
Si vous utilisez Docker, voici la configuration la plus simple pour démarrer :
# docker-compose.yml
version: '3.8'
services:
postgres:
image: pgvector/pgvector:pg16
environment:
POSTGRES_DB: rag_demo
POSTGRES_USER: postgres
POSTGRES_PASSWORD: password
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
volumes:
postgres_data:
Cette configuration utilise l’image officielle pgvector qui inclut déjà l’extension compilée et prête à l’emploi. L’avantage de cette approche est que vous évitez les complications de compilation manuelle de l’extension.
Création du projet Spring Boot
Créons maintenant notre projet Spring Boot avec les dépendances nécessaires. Le choix des dépendances est stratégique car il détermine les fonctionnalités disponibles et la simplicité d’intégration.
<!-- pom.xml -->
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>1.0.0-M4</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store-spring-boot-starter</artifactId>
<version>1.0.0-M4</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
La dépendance spring-ai-pgvector-store-spring-boot-starter est particulièrement importante car elle fournit l’intégration native entre Spring AI et pgvector, évitant ainsi de nombreuses configurations manuelles.
Configuration de l’application
La configuration de Spring AI nécessite quelques paramètres essentiels dans votre fichier application.yml. Ces configurations définissent comment votre application communiquera avec les services d’embedding et la base de données.
# application.yml
spring:
datasource:
url: jdbc:postgresql://localhost:5432/rag_demo
username: postgres
password: password
jpa:
hibernate:
ddl-auto: create-drop
show-sql: true
ai:
openai:
api-key: ${OPENAI_API_KEY}
embedding:
model: text-embedding-3-small
vectorstore:
pgvector:
index-type: HNSW
distance-type: COSINE_DISTANCE
dimensions: 1536
La configuration dimensions: 1536 correspond aux dimensions du modèle text-embedding-3-small d’OpenAI. Cette correspondance exacte est cruciale car une différence de dimensions causera des erreurs lors de l’insertion des vecteurs.
Modélisation des données
Comprenons maintenant comment structurer nos données pour optimiser les performances et la flexibilité de notre système RAG.
Entité Document
Notre entité Document représente les informations que nous voulons indexer et rechercher. La conception de cette entité influence directement les capacités de recherche de notre système.
@Entity
@Table(name = "documents")
public class Document {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(columnDefinition = "TEXT")
private String content;
@Column(columnDefinition = "TEXT")
private String title;
@Column(name = "source_url")
private String sourceUrl;
@Column(name = "created_at")
private LocalDateTime createdAt;
// Le vecteur sera géré par Spring AI VectorStore
// Pas besoin de le mapper directement dans l'entité
// Constructeurs, getters, setters
public Document() {}
public Document(String title, String content, String sourceUrl) {
this.title = title;
this.content = content;
this.sourceUrl = sourceUrl;
this.createdAt = LocalDateTime.now();
}
// ... getters et setters
}
Notez que nous ne mappons pas directement le vecteur dans l’entité JPA. Spring AI gère cette complexité pour nous à travers son abstraction VectorStore. Cette approche simplifie grandement le code tout en conservant la flexibilité.
Notes : Cette entité bénéficie automatiquement du cache de premier niveau JPA et Hibernate, ce qui optimise les performances lors des accès répétés aux mêmes documents.
Repository JPA
Le repository utilise les fonctionnalités standard de Spring Data JPA pour les opérations CRUD classiques. Les opérations vectorielles seront gérées séparément par Spring AI.
@Repository
public interface DocumentRepository extends JpaRepository<Document, Long> {
// Recherche textuelle traditionnelle pour comparaison
@Query("SELECT d FROM Document d WHERE " +
"LOWER(d.title) LIKE LOWER(CONCAT('%', :query, '%')) OR " +
"LOWER(d.content) LIKE LOWER(CONCAT('%', :query, '%'))")
List<Document> findByKeywords(@Param("query") String query);
// Recherche par source pour filtrer les résultats
List<Document> findBySourceUrlContaining(String sourceUrl);
// Documents récents pour la pertinence temporelle
List<Document> findByCreatedAtAfter(LocalDateTime date);
}
Ces méthodes permettent de combiner recherche vectorielle et filtres traditionnels, une approche hybride souvent nécessaire en production.
Service de vectorisation et stockage
Ce qui est important pour notre système RAG c’est la transformation des documents en vecteurs et leur stockage efficace. Comprenons comment Spring AI simplifie ces opérations complexes.
Service de gestion des documents
@Service
@Transactional
public class DocumentService {
private final DocumentRepository documentRepository;
private final VectorStore vectorStore;
private final EmbeddingModel embeddingModel;
private static final Logger logger = LoggerFactory.getLogger(DocumentService.class);
public DocumentService(DocumentRepository documentRepository,
VectorStore vectorStore,
EmbeddingModel embeddingModel) {
this.documentRepository = documentRepository;
this.vectorStore = vectorStore;
this.embeddingModel = embeddingModel;
}
/**
* Ajoute un document au système avec vectorisation automatique
* Cette méthode combine stockage relationnel et vectoriel
*/
public Document addDocument(String title, String content, String sourceUrl) {
// 1. Sauvegarder le document en base relationnelle
Document document = new Document(title, content, sourceUrl);
document = documentRepository.save(document);
// 2. Créer le vecteur pour Spring AI
// Nous combinons titre et contenu pour une représentation plus riche
String textToEmbed = title + "\n\n" + content;
org.springframework.ai.document.Document aiDocument =
new org.springframework.ai.document.Document(
document.getId().toString(),
textToEmbed,
Map.of(
"title", title,
"sourceUrl", sourceUrl != null ? sourceUrl : "",
"createdAt", document.getCreatedAt().toString()
)
);
// 3. Stocker dans le VectorStore
try {
vectorStore.add(List.of(aiDocument));
logger.info("Document vectorisé et ajouté avec succès: {}", document.getId());
} catch (Exception e) {
logger.error("Erreur lors de la vectorisation du document: {}", document.getId(), e);
// En cas d'erreur, on pourrait choisir de supprimer le document
// de la base relationnelle pour maintenir la cohérence
throw new RuntimeException("Échec de la vectorisation", e);
}
return document;
}
/**
* Traite un document long en le découpant en chunks
* Cette approche est essentielle pour les documents volumineux
*/
public Document addLargeDocument(String title, String content, String sourceUrl) {
Document document = new Document(title, content, sourceUrl);
document = documentRepository.save(document);
// Découpage en chunks de 1000 caractères avec overlap de 200
List<String> chunks = splitIntoChunks(content, 1000, 200);
List<org.springframework.ai.document.Document> aiDocuments = new ArrayList<>();
for (int i = 0; i < chunks.size(); i++) {
String chunkId = document.getId() + "_chunk_" + i;
String chunkContent = title + "\n\n" + chunks.get(i);
aiDocuments.add(new org.springframework.ai.document.Document(
chunkId,
chunkContent,
Map.of(
"title", title,
"sourceUrl", sourceUrl != null ? sourceUrl : "",
"createdAt", document.getCreatedAt().toString(),
"parentDocumentId", document.getId().toString(),
"chunkIndex", String.valueOf(i),
"totalChunks", String.valueOf(chunks.size())
)
));
}
vectorStore.add(aiDocuments);
logger.info("Document volumineux traité en {} chunks: {}", chunks.size(), document.getId());
return document;
}
/**
* Découpe intelligente du texte en préservant les phrases
*/
private List<String> splitIntoChunks(String text, int maxChunkSize, int overlap) {
List<String> chunks = new ArrayList<>();
String[] sentences = text.split("\\. ");
StringBuilder currentChunk = new StringBuilder();
for (String sentence : sentences) {
// Si ajouter cette phrase dépasse la taille max
if (currentChunk.length() + sentence.length() > maxChunkSize) {
if (currentChunk.length() > 0) {
chunks.add(currentChunk.toString().trim());
// Créer l'overlap en gardant les derniers mots
String[] words = currentChunk.toString().split(" ");
int overlapWords = Math.min(overlap / 10, words.length / 2);
currentChunk = new StringBuilder();
for (int i = words.length - overlapWords; i < words.length; i++) {
currentChunk.append(words[i]).append(" ");
}
}
}
currentChunk.append(sentence).append(". ");
}
// Ajouter le dernier chunk
if (currentChunk.length() > 0) {
chunks.add(currentChunk.toString().trim());
}
return chunks;
}
}
Cette implémentation montre comment Spring AI simplifie la gestion des vecteurs. Le VectorStore s’occupe automatiquement de la génération des embeddings et de leur stockage dans PostgreSQL avec pgvector.
Notes : Pour traiter efficacement de gros volumes de documents, considérez les opérations en masse avec JPA et Hibernate qui permettent d’optimiser les performances lors des insertions multiples.
Service de recherche sémantique
La recherche sémantique est le cœur de notre système RAG. Voici comment implémenter différents types de recherches pour répondre à divers besoins utilisateur.
Service de recherche avancée
@Service
public class SearchService {
private final VectorStore vectorStore;
private final DocumentRepository documentRepository;
private static final Logger logger = LoggerFactory.getLogger(SearchService.class);
public SearchService(VectorStore vectorStore, DocumentRepository documentRepository) {
this.vectorStore = vectorStore;
this.documentRepository = documentRepository;
}
/**
* Recherche sémantique pure basée sur la similarité vectorielle
*/
public List<SearchResult> semanticSearch(String query, int limit) {
try {
// Spring AI effectue automatiquement:
// 1. La vectorisation de la requête
// 2. La recherche par similarité
// 3. Le classement des résultats
List<org.springframework.ai.document.Document> results =
vectorStore.similaritySearch(SearchRequest.query(query).withTopK(limit));
return results.stream()
.map(this::convertToSearchResult)
.collect(Collectors.toList());
} catch (Exception e) {
logger.error("Erreur lors de la recherche sémantique: {}", query, e);
return Collections.emptyList();
}
}
/**
* Recherche hybride combinant sémantique et filtres métadata
*/
public List<SearchResult> hybridSearch(String query,
String sourceFilter,
LocalDateTime dateAfter,
int limit) {
// Construction du filtre dynamique
Filter.Builder filterBuilder = Filter.builder();
if (sourceFilter != null && !sourceFilter.isEmpty()) {
filterBuilder.eq("sourceUrl", sourceFilter);
}
if (dateAfter != null) {
filterBuilder.gte("createdAt", dateAfter.toString());
}
SearchRequest searchRequest = SearchRequest.query(query)
.withTopK(limit)
.withFilterExpression(filterBuilder.build());
List<org.springframework.ai.document.Document> results =
vectorStore.similaritySearch(searchRequest);
return results.stream()
.map(this::convertToSearchResult)
.collect(Collectors.toList());
}
/**
* Recherche avec seuil de similarité pour filtrer les résultats peu pertinents
*/
public List<SearchResult> searchWithThreshold(String query,
double similarityThreshold,
int limit) {
SearchRequest searchRequest = SearchRequest.query(query)
.withTopK(limit * 2) // Récupérer plus de résultats pour filtrer
.withSimilarityThreshold(similarityThreshold);
List<org.springframework.ai.document.Document> results =
vectorStore.similaritySearch(searchRequest);
// Spring AI filtre automatiquement selon le seuil
return results.stream()
.limit(limit)
.map(this::convertToSearchResult)
.collect(Collectors.toList());
}
/**
* Recherche pour RAG : optimisée pour fournir du contexte à un LLM
*/
public String getContextForRAG(String query, int maxContextLength) {
List<SearchResult> results = semanticSearch(query, 5);
StringBuilder context = new StringBuilder();
for (SearchResult result : results) {
String snippet = "Source: " + result.getTitle() + "\n" +
result.getContent() + "\n\n";
if (context.length() + snippet.length() > maxContextLength) {
break;
}
context.append(snippet);
}
return context.toString();
}
private SearchResult convertToSearchResult(org.springframework.ai.document.Document doc) {
Map<String, Object> metadata = doc.getMetadata();
return SearchResult.builder()
.id(doc.getId())
.content(doc.getContent())
.title((String) metadata.get("title"))
.sourceUrl((String) metadata.get("sourceUrl"))
.similarity(((Number) metadata.get("distance")).doubleValue())
.build();
}
}
Classe SearchResult
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class SearchResult {
private String id;
private String content;
private String title;
private String sourceUrl;
private double similarity;
private Map<String, Object> metadata;
/**
* Retourne un extrait du contenu pour l'affichage
*/
public String getSnippet(int maxLength) {
if (content.length() <= maxLength) {
return content;
}
String truncated = content.substring(0, maxLength);
int lastSpace = truncated.lastIndexOf(' ');
return lastSpace > 0 ?
truncated.substring(0, lastSpace) + "..." :
truncated + "...";
}
}
API REST pour l’interaction
L’interface REST permet à d’autres applications d’interagir facilement avec notre système RAG. Une API bien conçue facilite l’intégration et les tests.
Contrôleur principal
@RestController
@RequestMapping("/api/v1")
@CrossOrigin(origins = "*")
public class RAGController {
private final DocumentService documentService;
private final SearchService searchService;
private final ChatModel chatModel; // Pour la génération RAG complète
public RAGController(DocumentService documentService,
SearchService searchService,
ChatModel chatModel) {
this.documentService = documentService;
this.searchService = searchService;
this.chatModel = chatModel;
}
/**
* Ajouter un document au système
*/
@PostMapping("/documents")
public ResponseEntity<Document> addDocument(@RequestBody AddDocumentRequest request) {
try {
Document document = documentService.addDocument(
request.getTitle(),
request.getContent(),
request.getSourceUrl()
);
return ResponseEntity.ok(document);
} catch (Exception e) {
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).build();
}
}
/**
* Recherche sémantique simple
*/
@GetMapping("/search")
public ResponseEntity<List<SearchResult>> search(
@RequestParam String query,
@RequestParam(defaultValue = "10") int limit) {
List<SearchResult> results = searchService.semanticSearch(query, limit);
return ResponseEntity.ok(results);
}
/**
* Recherche hybride avec filtres
*/
@PostMapping("/search/hybrid")
public ResponseEntity<List<SearchResult>> hybridSearch(@RequestBody HybridSearchRequest request) {
List<SearchResult> results = searchService.hybridSearch(
request.getQuery(),
request.getSourceFilter(),
request.getDateAfter(),
request.getLimit()
);
return ResponseEntity.ok(results);
}
/**
* Endpoint RAG complet : recherche + génération
*/
@PostMapping("/rag/chat")
public ResponseEntity<RAGResponse> ragChat(@RequestBody RAGRequest request) {
try {
// 1. Récupérer le contexte pertinent
String context = searchService.getContextForRAG(request.getQuestion(), 4000);
// 2. Construire le prompt avec contexte
String prompt = buildRAGPrompt(request.getQuestion(), context);
// 3. Générer la réponse avec le LLM
String response = chatModel.call(prompt);
// 4. Récupérer les sources pour transparence
List<SearchResult> sources = searchService.semanticSearch(request.getQuestion(), 3);
return ResponseEntity.ok(RAGResponse.builder()
.answer(response)
.sources(sources)
.contextUsed(context.length() > 0)
.build());
} catch (Exception e) {
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR)
.body(RAGResponse.builder()
.answer("Désolé, je n'ai pas pu traiter votre question.")
.contextUsed(false)
.build());
}
}
private String buildRAGPrompt(String question, String context) {
return String.format("""
Vous êtes un assistant IA spécialisé dans l'analyse de documents.
Contexte pertinent:
%s
Question: %s
Instructions:
- Répondez uniquement basé sur le contexte fourni
- Si l'information n'est pas dans le contexte, dites-le clairement
- Citez les sources quand possible
- Soyez précis et concis
Réponse:
""", context, question);
}
}
Classes de requête et réponse
// Requêtes
@Data
public class AddDocumentRequest {
private String title;
private String content;
private String sourceUrl;
}
@Data
public class HybridSearchRequest {
private String query;
private String sourceFilter;
private LocalDateTime dateAfter;
private int limit = 10;
}
@Data
public class RAGRequest {
private String question;
private int maxSources = 5;
}
// Réponses
@Data
@Builder
public class RAGResponse {
private String answer;
private List<SearchResult> sources;
private boolean contextUsed;
private String debugInfo; // Optionnel pour le débogage
}
Exemple d’utilisation complète
Voyons maintenant comment utiliser notre système RAG dans un scénario réel avec des données d’exemple.
Initialisation avec des données de test
@Component
public class DataInitializer {
private final DocumentService documentService;
public DataInitializer(DocumentService documentService) {
this.documentService = documentService;
}
@EventListener(ApplicationReadyEvent.class)
public void initializeData() {
// Documents sur Spring Boot
documentService.addDocument(
"Guide Spring Boot Configuration",
"Spring Boot utilise la configuration automatique pour simplifier le développement. " +
"Les propriétés peuvent être définies dans application.yml ou application.properties. " +
"L'annotation @ConfigurationProperties permet de mapper les propriétés vers des objets Java.",
"https://spring.io/guides"
);
documentService.addDocument(
"Spring AI Vector Stores",
"Spring AI fournit une abstraction pour les bases de données vectorielles. " +
"Supports include pgvector, Pinecone, Weaviate, and ChromaDB. " +
"Le VectorStore interface simplifie les opérations de recherche sémantique.",
"https://docs.spring.io/spring-ai/reference/api/vectordbs.html"
);
// Documents sur PostgreSQL
documentService.addDocument(
"PostgreSQL Performance Tuning",
"Pour optimiser PostgreSQL, configurez shared_buffers à 25% de la RAM. " +
"Utilisez des index appropriés et analysez les requêtes avec EXPLAIN. " +
"La maintenance régulière avec VACUUM et ANALYZE est essentielle.",
"https://postgresql.org/docs"
);
}
}
Tests d’intégration
@SpringBootTest
@TestPropertySource(properties = {
"spring.ai.openai.api-key=test-key",
"spring.datasource.url=jdbc:h2:mem:testdb"
})
class RAGIntegrationTest {
@Autowired
private DocumentService documentService;
@Autowired
private SearchService searchService;
@Test
void shouldAddAndSearchDocuments() {
// Ajouter un document
Document doc = documentService.addDocument(
"Test Document",
"This is a test document about Spring AI and vector databases.",
"test-url"
);
assertThat(doc.getId()).isNotNull();
// Rechercher le document
List<SearchResult> results = searchService.semanticSearch("Spring AI", 5);
assertThat(results).isNotEmpty();
assertThat(results.get(0).getTitle()).contains("Test Document");
}
@Test
void shouldPerformHybridSearch() {
// Ajouter plusieurs documents avec différentes sources
documentService.addDocument("Doc 1", "Content about Spring", "source1");
documentService.addDocument("Doc 2", "Content about PostgreSQL", "source2");
// Recherche filtrée par source
List<SearchResult> results = searchService.hybridSearch(
"database", "source2", null, 10
);
assertThat(results).hasSize(1);
assertThat(results.get(0).getSourceUrl()).isEqualTo("source2");
}
}
Optimisations et bonnes pratiques
Gestion des performances
Pour un système RAG performant en production, plusieurs optimisations sont essentielles :
@Configuration
public class RAGOptimizationConfig {
/**
* Pool de threads pour les opérations de vectorisation asynchrones
*/
@Bean
@Primary
public TaskExecutor embeddingTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4);
executor.setMaxPoolSize(8);
executor.setQueueCapacity(100);
executor.setThreadNamePrefix("embedding-");
executor.initialize();
return executor;
}
/**
* Cache pour les embeddings fréquemment utilisés
*/
@Bean
public CacheManager cacheManager() {
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
cacheManager.setCaffeine(Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(Duration.ofHours(24)));
return cacheManager;
}
}
Service de vectorisation avec cache
@Service
public class OptimizedEmbeddingService {
private final EmbeddingModel embeddingModel;
@Cacheable(value = "embeddings", key = "#text.hashCode()")
public List<Float> getEmbedding(String text) {
// Évite de recalculer les embeddings pour le même texte
return embeddingModel.embed(text);
}
@Async("embeddingTaskExecutor")
public CompletableFuture<Void> processDocumentAsync(Document document) {
// Traitement asynchrone pour ne pas bloquer l'API
return CompletableFuture.runAsync(() -> {
// Vectorisation du document
});
}
}
Conclusion de l’implémentation
Cette implémentation complète démontre comment Spring AI simplifie considérablement le développement d’applications RAG. Les points clés à retenir sont :
Spring AI apporte une abstraction puissante qui masque la complexité des opérations vectorielles tout en conservant la flexibilité nécessaire pour les cas d’usage avancés.
L’intégration avec PostgreSQL et pgvector permet de bénéficier d’une base de données relationnelle familière tout en ajoutant des capacités de recherche sémantique performantes.
L’architecture modulaire facilite les tests, la maintenance et l’évolution du système. Chaque composant a une responsabilité claire et peut être modifié indépendamment.
Les performances sont optimisables grâce à la mise en cache, au traitement asynchrone et aux filtres hybrides qui combinent recherche vectorielle et critères traditionnels.
Ce système RAG est maintenant prêt pour la production et peut être étendu selon vos besoins spécifiques : ajout de nouveaux types de documents, intégration avec d’autres sources de données, ou optimisation pour des domaines métier particuliers.
Dans le prochain article, nous explorerons les techniques avancées d’optimisation des performances et les stratégies de déploiement en production.
Ping : Faire du RAG en Java avec LangChain4J - java-facile.fr