J’ai précédemment montré, dans un article dédié, comment faire du RAG (Retrieval-Augmented Generation) avec Spring AI et une base de données vectorielle Postgres. Aujourd’hui, je vais vous présenter comment faire du RAG grâce à une autre technologie, la librairie Open source : LangChain4J.
Commençons par définir ce qu’est un système RAG. Pour cela je vais reprendre la définition présentée dans la page de documentation de LangChain4J : https://docs.langchain4j.dev/tutorials/rag.
Qu’est-ce qu’un LLM et pourquoi RAG ?
Un LLM (Large Language Model) est un modèle d’intelligence artificielle capable de comprendre et générer du texte en langage naturel. Cependant, il reste limité aux données sur lesquelles il a été entraîné. Pour qu’un service basé sur un LLM puisse exploiter et comprendre vos données propriétaires, il est possible d’y intégrer un système de type RAG (Retrieval-Augmented Generation).
Qu’est-ce qu’un système RAG ?
Un système RAG permet d’enrichir un prompt en y intégrant des informations pertinentes avant de l’envoyer à un LLM.
Pour que le LLM accède à vos données propriétaires, il existe plusieurs méthodes :
- Full-text search : une recherche documentaire qui fonctionne en faisant matcher les mots-clés de la requête (supporté par Azure AI).
- Vector search : une recherche vectorielle qui vérifie la correspondance du prompt avec les données de façon sémantique. C’est ce que nous avions utilisé dans notre précédent article, et c’est ce qui est principalement utilisé dans LangChain4J.
- Hybrid : c’est une combinaison des deux précédentes méthodes.
Dans cet article, nous nous intéresserons à la recherche vectorielle.
Pour vectoriser vos informations métier, il y a une phase d’indexation à réaliser. Cette phase sera détaillée dans la section suivante.
Phase d’indexation
La phase d’indexation dépend largement des informations que vous utiliserez : documents Word, PDF, TXT ou images etc. Cette phase d’indexation est principalement réalisée hors ligne, c’est-à-dire en dehors du système ou de l’application qui interagit avec le LLM ou bien en amont de la requête de l’utilisateur.
Pour des questions pratiques, notre phase d’indexation dans l’exemple suivant sera intégré à l’application Java et se fera au moment de l’envoi de la question au LLM. Comme vous l’avez compris, ce n’est pas une bonne pratique.
Pour que les informations soient compréhensible par LLM, il faut d’abord découper les documents en segment puis transformer ses segments en représentation mathématiques (vecteurs). Comme présenter dans les schémas suivants :
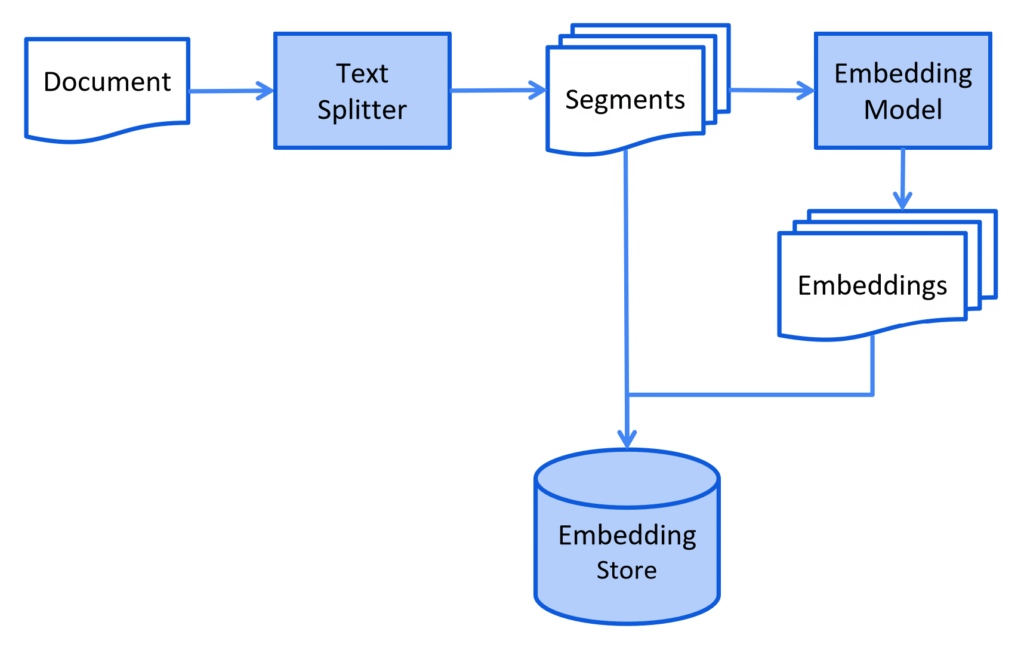
Les segments
Les segments sont des morceaux de texte découpés à partir de vos documents source. C’est la première étape du processus :
- Vous prenez un document long (PDF, article, etc.)
- Vous le divisez en petits morceaux cohérents (paragraphes, sections, phrases)
- Chaque morceau devient un « segment » ou « chunk »
Par exemple, si vous avez un manuel de 100 pages, vous pourriez le découper en 200 segments de quelques phrases chacun.
Les embeddings
Les embeddings sont des représentations numériques de ces segments. Pour chaque segment :
- Le texte est transformé en vecteur (liste de nombres)
- Ce vecteur capture le « sens » du texte dans un espace mathématique
- Des textes similaires auront des vecteurs proches
Par exemple, le segment « Le chat dort sur le canapé » pourrait devenir un vecteur comme [0.2, -0.8, 0.4, …] avec des centaines de dimensions.
Phase de récupération
Une fois vos données segmentées et vectorisées, vous obtenez une base de données, ou autre système de stockage, avec vos Embeddings accessibles. Vient ensuite la phase de récupération, elle s’opère le plus souvent online : quand l’utilisateur pose une question au LLM.
Ce procédé dépend du type d’informations récupérées, mais peut-être représenté, la plupart du temps, par le diagramme suivant :
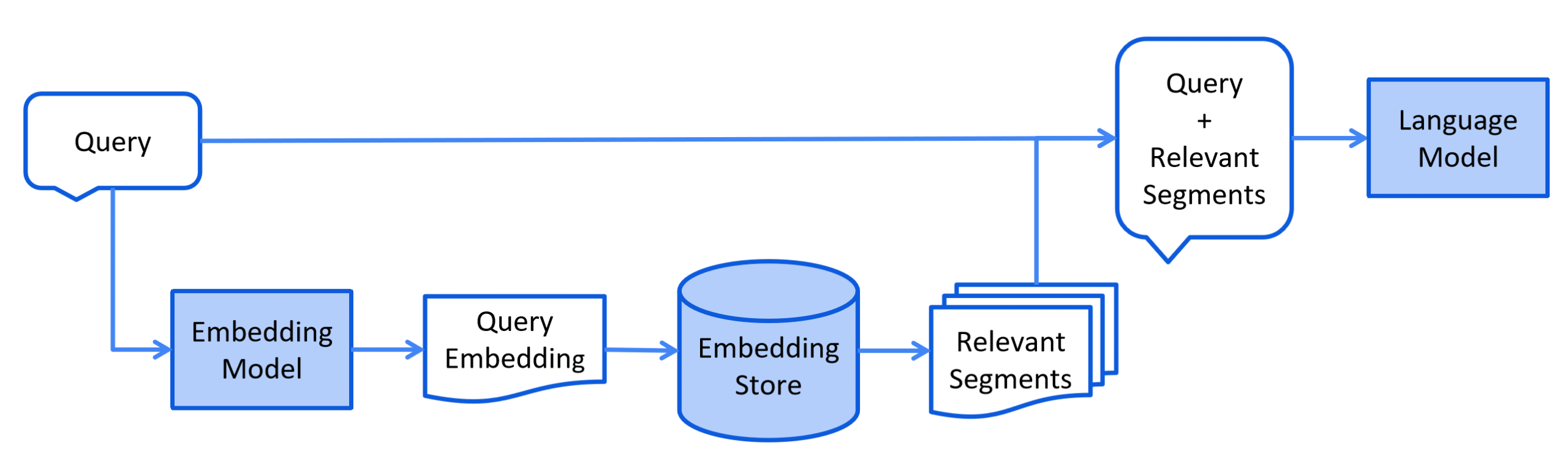
Dans le diagramme, on voit bien que la requête utilisateur, avant d’être envoyé au LLM, passe par un Embedding modèle pour récupérer les segments pertinents et les ajouter au contexte dans prompt.
C’est ainsi que le LLM a accès à vos données propriétaires. Passons maintenant à l’implémentation.
Implémentation du RAG
Pour commencer facilement un RAG, et pour commencer à manipuler ce type d’architecture, LangChain4J dispose d’une bibliothèque intitulée : Easy RAG.
Imports
Commençons par importer dans notre pom.xml, la dépendance Easy Rag :
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.3.0-beta9</version>
</dependency>
Nous aurons aussi besoin de la librairie LangChain4J Open AI :
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.3.0</version>
</dependency>
Ainsi que la librairie LangChain4J Document Parser Apache POI, car nos documents sources sont des documents Word :
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-poi</artifactId>
<version>1.3.0-beta9</version>
</dependency>
Chargement des documents
Pour charger les documents, il existe une classe utilitaire : FileSystemDocumentLoader.
Cette classe implémente directement la fonctionnalité de chargement de documents depuis le système de fichiers.
Pour charger facilement les documents d’un répertoire, cette ligne de code suffit :
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j/documentation");
La méthode loadDocuments peut aussi prendre un parser en paramètre par exemple le parser d’Apache POI (précédemment importé) :
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j/documentation", new ApachePoiDocumentParser());
Embedding store
Nous avons maintenant besoin de stocker les documents dans un store, par exemple une base vectorielle, pour ainsi trouver facilement les morceaux d’information pertinents. La librairie Easy RAG supporte un store en mémoire pour tester facilement le système : InMemoryEmbeddingStore.
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>(); EmbeddingStoreIngestor.ingest(documents, embeddingStore);
La méthode ingest va utiliser un EmbeddingStoreIngestor qui charge un DocumentSplitter qui découpe les documents chargés en segments.
Création du service
La dernière étape consiste à coder ce qui va nous servir à interroger le LLM.
L’exemple ci-dessous est fourni par la librairie et illustre parfaitement cette dernière étape :
interface Assistant {
String chat(String userMessage);
}
ChatModel chatModel = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName(GPT_4_O_MINI)
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatModel(chatModel)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore))
.build();
On définit une interfaces qui représente notre assistant, on déclare un modèle de chat ici via un builder, Open Eye. Et enfin on implémente notre assistant en lui donnant le modèle quelques paramètres et notre embedding store avec la méthode contentRetriever.
Un exemple plus concret, sera présenté dans la suite de l’article.
Avec la dernière ligne de code suivante, on peut envoyer une requête au LLM :
String answer = assistant.chat("How to do Easy RAG with LangChain4j?");
Cette requête sera accompagnée d’un contexte pertinent, à partir de jeux de données fournis par le RAG.
Exemple plus concret : usage et limite
Bien, vous savez maintenant comment implémenter un système RAG en Java avec la librairie LangChain4J. Prenons pour exemple un contexte plus réaliste et vérifiant si cela fonctionne.
Je dispose de données non accessible sur Internet, via le manuscrit de mon dernier livre, édité aux éditions ENI :

Le code complet de l’implémentation présenté ci-dessous est disponible sur GitHub à l’adresse suivante : https://github.com/gantoin/java-facile-easy-rag.
D’abord, je donne le chemin du répertoire qui contient tous mes manuscrits :
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/Users/antoinegauthier/Documents/ENI/texte", new ApachePoiDocumentParser());
J’utilise le parser adéquat ApachePoiDocumentParser, mais manuscrits sont au format Microsoft Word.
Implémentation de l’assistant
Je lui donne ensuite mon API KEY, comme présenter dans la documentation de LangChain4J j’utilise le modèle GPT_4_O_MINI d’OpenAI.
Plus qu’à donner la question suivante au LLM : « Quelle est l’organisation exacte du code présentée dans la classe EmplacementDesVariables ? » ; j’attends la réponse suivante se trouve au deuxième chapitre de mon livre Java
Les fondamentaux du langage (avec exercices pratiques et corrigés) (2e édition) :
public class EmplacementDesVariables {
// variable d'instance
int instanceVariable;
// variable de classe
static int classVariable;
void uneMethode(int parametre) {
// variable locale
int locale = 0;
}
}
Je compile, je run, j’attends, et je constate la réponse du LLM :
La classe `EmplacementDesVariables` semble être conçue pour illustrer l'organisation et la portée des différentes types de variables en Java. Voici une vue d'ensemble de la structure que l'on pourrait attendre pour cette classe, basée sur les informations fournies :
```java
public class EmplacementDesVariables {
// Déclaration d'une variable de classe (statique)
static int variableDeClasse;
// Déclaration d'une variable d'instance
int variableDInstance;
// Constructeur de la classe
public EmplacementDesVariables(int valeur) {
// Initialisation de la variable d'instance
this.variableDInstance = valeur;
// Code d'initialisation supplémentaire pourrait être ici si nécessaire
}
...
La réponse n’est pas correcte. Le LLM a halluciné. Il a « imaginé » un morceau de code.
Je vous épargne les longues minutes de débogage et de recherche nécessaires pour comprendre pourquoi cela ne fonctionnait pas comme prévu. La raison est la suivante : le découpage des documents en segments joue un rôle déterminant dans la qualité de votre jeu de données.
En effet, vous devez mettre à jour et vérifier manuellement vos jeux de données, car les chunks peuvent être mal générés. Par exemple, un paragraphe peut parfois se scinder en deux à un endroit inapproprié. C’est exactement le problème que j’ai rencontré : la génération a séparé un extrait de code de cette classe.
Configuration des modèles d’IA
Contrairement à l’approche basique de LangChain4J, j’ai rapidement réalisé qu’il était nécessaire de configurer explicitement les modèles d’embedding et de chat pour obtenir des résultats optimaux.
// Configuration explicite du modèle d'embedding
EmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
.apiKey("votre-api-key")
.modelName(OpenAiEmbeddingModelName.TEXT_EMBEDDING_3_SMALL)
.build();
// Configuration du modèle de chat
ChatModel chatModel = OpenAiChatModel.builder()
.apiKey("votre-api-key")
.modelName(OpenAiChatModelName.GPT_4_O_MINI)
.temperature(0.1) // Réduire la créativité pour plus de fidélité
.build();
Optimisation du chunking et de l’ingestion
L’un des aspects les plus critiques est la configuration de la segmentation des documents : EmbeddingStoreIngestor.
// Configuration de l'ingestor avec segmentation personnalisée
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(DocumentSplitters.recursive(1000, 300)) // chunks plus grands avec overlap important
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
ingestor.ingest(documents);
On s’assure que la taille des chunks est de 1000 caractères et que la taille de l’overlap est de 300 caractères. Ces paramètres sont cruciaux pour préserver, dans notre cas, l’intégrité des blocs de code et du contexte.
Configuration avancée du retriever
Étant donné que nous avons configuré explicitement un modèle d’Emdebbing, on doit également être configurer le retriever :
EmbeddingStoreContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(25) // Récupérer suffisamment de chunks
.minScore(0.3) // Score moins restrictif
.build();
Interface avec prompt système strict
On peut aussi forcer le modèle à utiliser uniquement les données fournies grâce à cette annotation :
public interface Assistant {
@SystemMessage("""
Tu es un assistant spécialisé dans les cours de programmation Java.
Tu dois UNIQUEMENT répondre en utilisant les informations contenues dans les documents fournis.
RÈGLES STRICTES :
- Si l'information n'est pas dans les documents fournis, dis "Je ne trouve pas cette information dans les documents fournis"
- Ne jamais inventer ou compléter avec tes connaissances générales
- Cite exactement le code et les exemples tels qu'ils apparaissent dans les documents
""")
String chat(@UserMessage String userMessage);
}
Le résultat final
Après ces optimisations, le système RAG fonctionne parfaitement et retourne exactement le code attendu :
L'organisation exacte du code présentée dans la classe `EmplacementDesVariables` est la suivante :
```java
public class EmplacementDesVariables {
// variable d'instance
int instanceVariable;
// variable de classe
static int classVariable;
void uneMethode(int parametre) {
// variable locale
int locale = 0;
}
}
Leçons apprises
Le développement d’un RAG performant nécessite :
- Configuration explicite des modèles : ne pas se fier aux paramètres par défaut
- Tuning minutieux du chunking : adapter la taille et l’overlap au type de contenu
- Tests et debugging systématiques : vérifier ce qui est réellement récupéré
- Patience et itération : 80% du travail consiste à optimiser les données et la récupération
En effet, il est essentiel de mettre à jour et de vérifier manuellement vos jeux de données. Les chunks peuvent être mal générés. Il arrive, par exemple, qu’un paragraphe soit scindé en deux à un endroit inapproprié. C’est exactement le problème que j’ai rencontré : le code de cette classe avait été séparé de son contexte théorique.
La vraie difficulté du RAG n’est pas technique, mais méthodologique : c’est un travail d’ingénierie des données plus que d’intelligence artificielle.
Alors que le travail d’ingénierie logiciel risque d’être fortement impacté par l’arrivée des modèles hyper intelligents, le travail des data scientists mettre à jour et vérifier les jeux de données des entreprises risquent d’exploser.
De la même manière que le marché a vu émerger un nouveau domaine d’expertise combinant développement et administration système (DevOps), pourrait-on voir apparaître un domaine alliant développement et data science ?
Pour aller plus loin : Articles complémentaires
Maintenant que vous maîtrisez les fondamentaux du RAG avec LangChain4J, voici une sélection d’articles du blog qui vous permettront d’approfondir vos connaissances sur les sujets connexes :
Architecture et Performance Java
Fuite Mémoire en Java : Comprendre et Maîtriser
Indispensable pour optimiser les performances de vos applications RAG. Comprendre la gestion mémoire devient crucial quand on traite de gros volumes de données vectorielles et d’embeddings.
ArrayList vs LinkedList en Java : Comprendre les différences fondamentales
Choisir la bonne structure de données pour stocker vos segments et documents peut considérablement impacter les performances de votre système RAG.
Gestion des Données avec JPA/Hibernate
Le cache de premier niveau JPA et Hibernate
Si vous envisagez de persister vos embeddings et métadonnées en base de données plutôt qu’en mémoire, cette lecture vous sera précieuse pour optimiser les accès aux données.
Mise à jour et suppression en masse avec JPA et Hibernate
Technique avancée pour gérer efficacement la mise à jour de vos index vectoriels quand vos données sources évoluent.
Évolutions du Langage Java
Nouveauté Java 25 : API Gatherer
La nouvelle API Gatherer pourrait révolutionner la façon dont nous traitons les flux de données dans nos pipelines RAG, notamment pour la phase de preprocessing des documents.
Java 25 : Import de Modules
Une fonctionnalité intéressante pour mieux organiser vos projets RAG complexes avec de nombreuses dépendances comme LangChain4J, OpenAI, et les parsers de documents.
Ces lectures complémentaires vous donneront les bases solides nécessaires pour construire des systèmes RAG robustes et performants en production.