
Cette article est une traduction de Bulk Update and Delete with JPA and Hibernate par Vlad Mihalcea
Introduction : Qu’est-ce que les opérations en masse ?
Avant de plonger dans les détails techniques, commençons par comprendre ce que signifient les « opérations en masse » dans le contexte des bases de données.
Qu’est-ce qu’une opération en masse ? Une opération en masse permet de modifier ou supprimer plusieurs enregistrements dans une base de données en une seule instruction SQL, plutôt que de traiter chaque enregistrement individuellement.
Pourquoi est-ce important ? Imaginons que vous ayez 10 000 articles de blog marqués comme « spam » que vous voulez supprimer. Vous avez deux approches :
- Approche inefficace : Récupérer chaque article un par un et le supprimer individuellement (10 000 requêtes SQL)
- Approche efficace : Utiliser une seule requête qui supprime tous les articles spam d’un coup (1 seule requête SQL)
La différence de performance est énorme !
JPA et Hibernate : Les outils de notre exemple
JPA (Java Persistence API) est une spécification Java qui définit comment gérer les données relationnelles dans les applications Java. Pensez-y comme à un « contrat » ou un « mode d’emploi » standardisé.
Hibernate est une implémentation concrète de JPA. C’est l’outil qui fait réellement le travail, comme une voiture qui respecte les normes de sécurité routière (JPA étant les normes, Hibernate étant la voiture).
Deux stratégies pour modifier plusieurs enregistrements
1. Le traitement par lots (Batch Processing)
Cette approche est utile quand vous avez déjà chargé les entités en mémoire dans votre application. Elle regroupe plusieurs opérations et les envoie à la base de données par « paquets », réduisant ainsi le nombre d’allers-retours réseau.
2. Le traitement en masse (Bulk Processing)
Cette approche exécute directement une requête SQL qui modifie tous les enregistrements correspondants d’un coup, sans les charger en mémoire. C’est généralement plus rapide pour de gros volumes.
Notre modèle de données : Un système de modération
L’exemple utilise un système de blog avec modération. Voici les concepts clés :
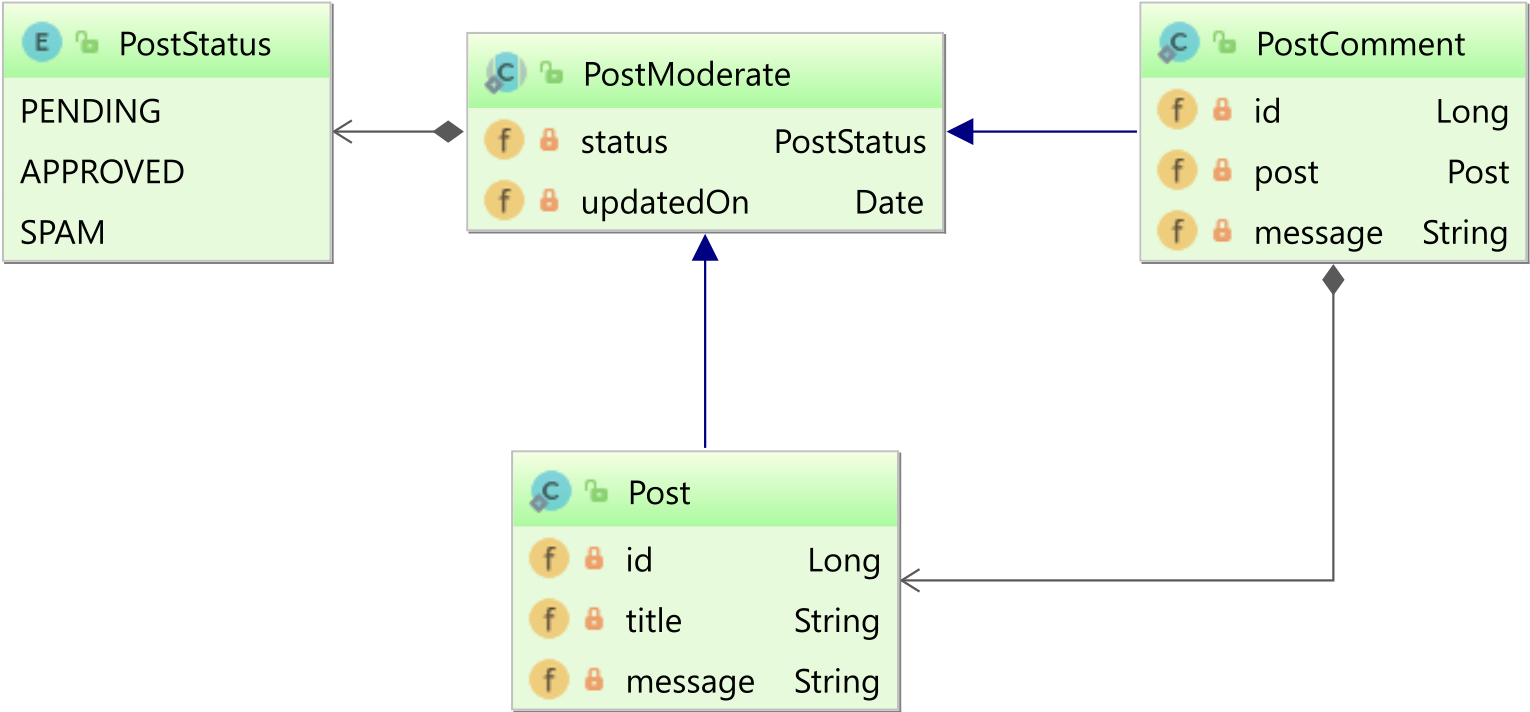
L’énumération PostStatus
// Cette énumération représente les différents états d'un contenu
enum PostStatus {
PENDING, // En attente de modération (valeur 0)
APPROVED, // Approuvé par un modérateur (valeur 1)
SPAM // Marqué comme spam (valeur 2)
}
Pourquoi utiliser des entiers plutôt que du texte ? Stocker 0, 1, 2 prend moins de place en base que "PENDING", "APPROVED", "SPAM" et les comparaisons sont plus rapides.
La classe parent PostModerate
@MappedSuperclass // Cette annotation indique que cette classe ne sera pas une table,
// mais que ses propriétés seront héritées par d'autres entités
public abstract class PostModerate<T extends PostModerate> {
@Enumerated(EnumType.ORDINAL) // Stocke l'enum comme un entier (0,1,2)
@Column(columnDefinition = "smallint") // Utilise le plus petit type entier possible
private PostStatus status = PostStatus.PENDING; // Valeur par défaut : en attente
@Column(name = "updated_on")
private Date updatedOn = new Date(); // Date de dernière modification
// Méthodes getter et setter...
}
Qu’est-ce que @MappedSuperclass ? C’est comme créer un « modèle » que d’autres classes peuvent réutiliser. La classe PostModerate ne deviendra pas une table en base de données, mais ses propriétés (status et updatedOn) seront ajoutées aux tables des classes qui l’héritent.
Les entités Post et PostComment
Ces deux classes héritent de PostModerate, ce qui signifie qu’elles auront automatiquement les champs status et updatedOn.
@Entity(name = "Post") // Indique que cette classe correspond à une table
@Table(name = "post") // Nom de la table en base de données
public class Post extends PostModerate<Post> {
@Id // Clé primaire
private Long id;
private String title; // Titre de l'article
private String message; // Contenu de l'article
// Méthodes getter et setter...
}
@Entity(name = "PostComment")
@Table(name = "post_comment")
public class PostComment extends PostModerate<PostComment> {
@Id
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
private Post post;
private String message;
public Long getId() {
return id;
}
// ...
}
Point important sur les associations : @ManyToOne et @OneToOne utilisent par défaut FetchType.EAGER, ce qui est mauvais pour les performances. Cela signifie que chaque fois que vous récupérez un PostComment, Hibernate récupère automatiquement le Post associé, même si vous n’en avez pas besoin.
Préparation des données de test
L’exemple crée quelques enregistrements pour démontrer les opérations :
// Un article approuvé (sera visible aux utilisateurs)
entityManager.persist(
new Post()
.setId(1L)
.setTitle("High-Performance Java Persistence")
.setStatus(PostStatus.APPROVED)
);
// Deux articles en attente avec du contenu suspect
entityManager.persist(
new Post()
.setId(2L)
.setTitle("Spam title") // Contient le mot "spam"
);
entityManager.persist(
new Post()
.setId(3L)
.setMessage("Spam message") // Contient le mot "spam"
);
// Un commentaire suspect
entityManager.persist(
new PostComment()
.setId(1L)
.setPost(entityManager.getReference(Post.class, 1L))
.setMessage("Spam comment") // Contient le mot "spam"
);
Mise à jour en masse avec JPQL
JPQL (Java Persistence Query Language) est un langage de requête similaire à SQL, mais qui travaille avec des objets Java plutôt qu’avec des tables.
Marquer les articles spam
int updateCount = entityManager.createQuery("""
update Post
set updatedOn = CURRENT_TIMESTAMP,
status = :newStatus
where status = :oldStatus
and (lower(title) like :spamToken
or lower(message) like :spamToken)
""")
.setParameter("newStatus", PostStatus.SPAM) // Nouveau statut : SPAM
.setParameter("oldStatus", PostStatus.PENDING) // Ancien statut : PENDING
.setParameter("spamToken", "%spam%") // Recherche le mot "spam"
.executeUpdate();
assertEquals(2, updateCount); // 2 articles ont été mis à jour
Décortiquons cette requête :
update Post: On veut modifier la table des articlesset updatedOn = CURRENT_TIMESTAMP, status = :newStatus: On met à jour la date et le statutwhere status = :oldStatus: Seulement les articles en attenteand (lower(title) like :spamToken or lower(message) like :spamToken): Qui contiennent « spam » dans le titre OU le message:newStatus,:oldStatus,:spamTokensont des paramètres qu’on définit séparément
Pourquoi utiliser des paramètres ? C’est plus sûr que de construire la requête avec des chaînes de caractères (évite les injections SQL) et permet la réutilisation de la requête.
SQL généré par Hibernate :
UPDATE post SET updated_on = CURRENT_TIMESTAMP, status = 2 WHERE status = 0 AND (lower(title) LIKE '%spam%' OR lower(message) LIKE '%spam%')
Notez comment Hibernate a traduit PostStatus.SPAM en 2 et PostStatus.PENDING en 0.
Mise à jour des commentaires
Le principe est identique pour les commentaires :
int updateCount = entityManager.createQuery("""
update PostComment
set updatedOn = CURRENT_TIMESTAMP,
status = :newStatus
where status = :oldStatus
and lower(message) like :spamToken
""")
.setParameter("newStatus", PostStatus.SPAM)
.setParameter("oldStatus", PostStatus.PENDING)
.setParameter("spamToken", "%spam%")
.executeUpdate();
assertEquals(1, updateCount); // 1 commentaire mis à jour
Suppression en masse avec JPQL
Supprimer les anciens articles spam
int deleteCount = entityManager.createQuery("""
delete from Post
where status = :status
and updatedOn <= :validityThreshold
""")
.setParameter("status", PostStatus.SPAM)
.setParameter(
"validityThreshold",
Timestamp.valueOf(LocalDateTime.now().minusDays(7))
)
.executeUpdate();
assertEquals(2, deleteCount); // 2 articles supprimés
Cette requête supprime :
- Tous les articles (
Post) - Qui ont le statut SPAM
- Et qui ont été mis à jour il y a plus de 7 jours
Calcul de la date limite :
LocalDateTime.now(): Date et heure actuelles.minusDays(7): Retire 7 joursTimestamp.valueOf(): Convertit en format compatible avec la base de données
Supprimer les anciens commentaires spam
Même principe pour les commentaires, mais avec un délai de 3 jours :
int deleteCount = entityManager.createQuery("""
delete from PostComment
where status = :status
and updatedOn <= :validityThreshold
""")
.setParameter("status", PostStatus.SPAM)
.setParameter(
"validityThreshold",
Timestamp.valueOf(LocalDateTime.now().minusDays(3))
)
.executeUpdate();
assertEquals(1, deleteCount); // 1 commentaire supprimé
Avantages des opérations en masse
Performance
Au lieu d’exécuter potentiellement des milliers de requêtes individuelles, vous n’en exécutez qu’une seule. C’est comme faire ses courses : plutôt que de faire 50 trajets pour acheter chaque article individuellement, vous faites une seule course pour tout acheter.
Simplicité
Le code est plus lisible et plus maintenable. Une requête claire exprime mieux l’intention que de multiples boucles et conditions.
Atomicité
Toute l’opération réussit ou échoue en bloc. Si quelque chose se passe mal au milieu, la base de données peut annuler toute l’opération.
Points d’attention pour les débutants
1. Les opérations en masse contournent le cache Hibernate
Hibernate maintient un cache des entités en mémoire. Les opérations en masse modifient directement la base de données sans mettre à jour ce cache. Si vous avez des entités en mémoire qui correspondent aux critères de vos opérations en masse, elles ne seront pas synchronisées automatiquement.
2. Pas de validation automatique
Contrairement aux opérations sur les entités individuelles, les opérations en masse ne déclenchent pas les validations Java (annotations @Valid, etc.) ni les callbacks JPA (@PreUpdate, @PostUpdate, etc.).
3. Transactions
Comme pour toute opération de modification en base de données, assurez-vous que vos opérations en masse sont exécutées dans une transaction appropriée.
Cas d’usage typiques
Les opérations en masse sont particulièrement utiles pour :
- Nettoyage périodique : Supprimer les anciennes données (logs, sessions expirées, etc.)
- Mise à jour de statuts : Changer le statut de plusieurs enregistrements selon des critères métier
- Corrections de données : Appliquer des corrections sur de gros volumes de données
- Archivage : Marquer des enregistrements comme archivés
- Modération de contenu : Comme dans notre exemple, traiter le spam en masse
Conclusion
Les opérations en masse avec JPA et Hibernate sont un outil puissant pour traiter efficacement de gros volumes de données. Elles vous permettent d’écrire du code plus performant et plus expressif, tout en restant dans l’écosystème JPA.
La clé est de savoir quand les utiliser : privilégiez les opérations en masse quand vous devez modifier de nombreux enregistrements selon des critères simples, et les opérations individuelles quand vous avez besoin de logique métier complexe ou de validations spécifiques pour chaque enregistrement.
N’oubliez pas que ces opérations sont très proches du SQL natif, ce qui signifie qu’elles sont rapides mais nécessitent une compréhension solide de votre modèle de données et de vos besoins métier.
Découvrez nos articles sur JPA juste ici ↓

Ping : Quarkus SFTP : Système de Fichiers Sécurisé avec Dev Services - java-facile.fr