Parmi les nouveautés les plus attendues de Java 25, on trouve l’introduction officielle de l’API des Stream Gatherers, une évolution majeure pour le traitement de flux de données (java.util.stream). Cette nouvelle API s’intègre directement à l’API Stream, que vous connaissez probablement déjà, et apporte une approche plus souple et expressive pour la transformation et l’agrégation de données.
Initialement introduite en tant que fonctionnalité en mode preview dans le JDK 24 de Java, les éléments Stream Gatherer deviennent pleinement intégrés et stabilisés avec Java 25, dont la sortie est prévue pour septembre 2025. Ce sera la prochaine version LTS (Long-Term Support) après Java 21, marquant une étape importante pour les développeurs qui souhaitent adopter les dernières innovations du langage tout en bénéficiant de la stabilité à long terme.
Stream Gatherers were proposed as a preview feature by JEP 461 in JDK 22 and re-previewed by JEP 473 in JDK 23. We here propose to finalize the API in JDK 24, without change.
https://openjdk.org/jeps/485
Dans cet article, nous allons explorer en profondeur cette nouvelle API, comprendre son utilité, son fonctionnement, et en quoi l’API complète — voire dépasse — certaines limites des collect() classiques des Stream.
- Stream Gatherers : Qu'est-ce que c'est ?
- Rappel : Qu'est-ce qu'un Stream ?
- Composition des Gatherers
- Implémentation d'un Stream Gatherer
- Nuance importante sur les Integrators Greedy
- Initialisation du state
- Finalisation avec un Finisher
- Gatherer.ofSequential
- Exemple concret : Gestion de produits dans une codebase Java
- Avantages dans contexte Java avancé
- Avantages des Stream Gatherer en général
- Conclusion
Stream Gatherers : Qu’est-ce que c’est ?
Les éléments Stream Gatherers sont détaillés dans la JEP 485. Une JEP, « JDK Enhancement Proposal », est un document d’explication d’une fonctionnalité du langage Java et non un document technique d’implémentation. Viktor Klang est l’ingénieur qui a conçu les éléments Stream Gatherers.
Enhance the Stream API to support custom intermediate operations. This will allow stream pipelines to transform data in ways that are not easily achievable with the existing built-in intermediate operations.
https://openjdk.org/jeps/485
Les éléments des streams Gatherer, bien qu’indépendants de l’API Stream, travaillent de pair avec celle-ci pour étendre ses capacités.
Rappel : Qu’est-ce qu’un Stream ?
Un Stream est une API livrée initialement dans la version JDK 8 de Java. C’est une interface qui modélise un objet qu’il faut connecter à une source de données : une Collection, des lignes d’un fichier, etc.
Un Stream définit deux types d’opérations :
Les opérations intermédiaires (intermediate operations)
Les opérations terminales (terminal operations)
L’opération correspond en réalité à une méthode appliquée sur un Stream. Si cette méthode retourne un autre Stream, alors c’est une opération intermédiaire ; si elle retourne autre chose, alors c’est une opération terminale.
Par exemple :
Les méthodes stream/Stream.html#findAny–« >findAny, stream/Stream.html#collect-java.util.stream.Collector-« >collect sont des opérations terminales.
Les méthodes stream/Stream.html#limit-long-« >limit, stream/Stream.html#flatMap-java.util.function.Function-« >flatMap sont des opérations intermédiaires.
Upstream vs. Downstream
Il est important de comprendre la notion d’upstream/downstream pour bien appréhender un élément des streams Gatherer.
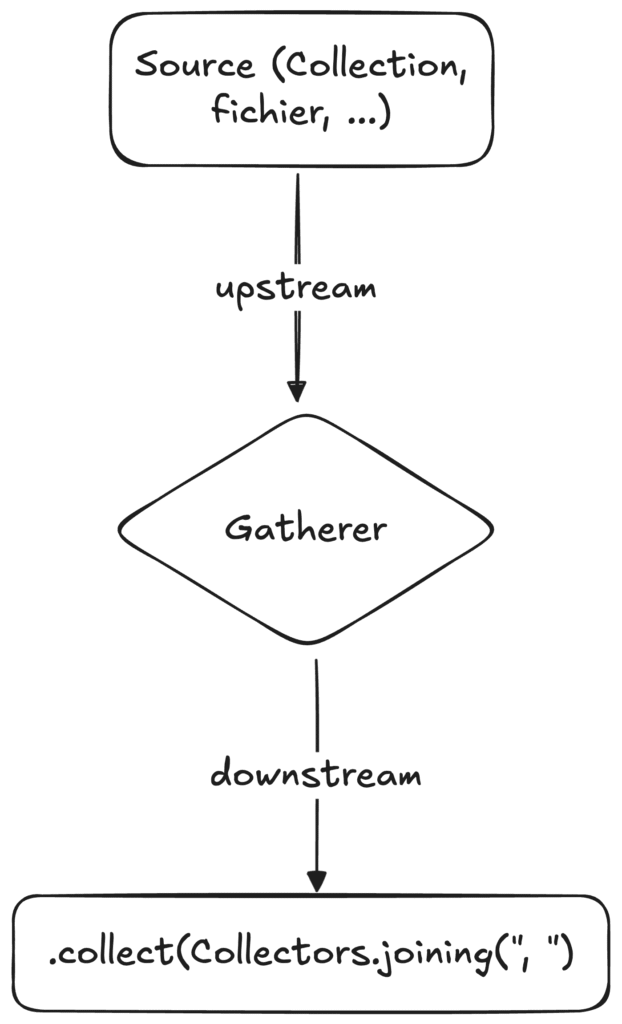
On parle d’upstream pour désigner les streams entrant dans une opération intermédiaire, tandis que le downstream désigne les streams en sortie.
Par exemple, la méthode sorted() va pousser l’élément dans le downstream une fois trié. Attention, cette opération a besoin de recevoir l’intégralité des éléments produits par la source (upstream) pour effectuer le tri.
Avant les éléments Stream Gatherer, nous n’avions pas de moyen de créer nos propres opérations intermédiaires. Vous l’avez compris, les éléments Stream Gatherer nous offre le moyen de créer des opérations intermédiaires personnalisées pour répondre à nos besoins fonctionnels.
Tableau comparatif
| Approche | Cas d’usage | Complexité | Réutilisabilité | Performance |
|---|---|---|---|---|
| Collectors | Agrégation finale | Faible | Moyenne | Haute |
| Opérations Stream | Transformations simples | Faible | Faible | Haute |
| Gatherers | Transformations complexes avec état | Moyenne | Haute | Haute |
| Boucles traditionnelles | Logique impérative | Variable | Faible | Haute |
| Reactive Streams | Flux asynchrones | Élevée | Haute | Variable |
Composition des Gatherers
L’API Gatherers se compose de trois éléments principaux :
- Interface Gatherer<T, A, R> : l’interface principale de l’API avec 3 paramètres (type générique), chacun jouant un rôle clé dans la définition de la function d’agrégation
- Opération intermédiaire Stream.gather(gatherer) : la méthode de l’API intègre le Gatherer dans le pipeline (de type stream) sous forme de function personnalisée
- Classe factory Gatherers : qui fournit des méthodes pour créer des Gatherers prêts à l’emploi
Le premier paramètre de type T représente le type des éléments de l’upstream, tandis que le troisième paramètre R représente le type des éléments que va retourner le downstream.
Exemple :
// T = String (type des éléments du stream en entrée)
Stream<String> upstream = Stream.of("a", "bb", "ccc");
// R = Integer (type des éléments du stream en sortie)
Gatherer<String, ?, Integer> gatherer = ...;
Stream<Integer> downstream = upstream.gather(gatherer);
Comment les éléments Stream Gatherer se comparent-t-ils aux Collectors ?
Attention : Le paramétrage de l’interface Gatherer<T, A, R> peut faire penser au paramétrage de l’interface Collector<T, A, R>. Cependant, étant donné que la méthode collect(collector) est une opération terminale, elle retourne le type R et non un Stream d’éléments de type R, comme illustré ci-dessous :
Stream<String> upstream = Stream.of("a", "bb", "ccc");
Collector<String, ?, Integer> collector = ...;
Integer result = upstream.collect(collector); // Retourne R, pas Stream<R>
Le Collector encapsule une function terminale de réduction, tandis que le Gatherer représente une function intermédiaire.
Implémentation d’un Stream Gatherer
Pour implémenter un Stream Gatherer, il faut comprendre une nouvelle notion apportée par la JEP 485 : l’interface Integrator<A, T, R>.
En effet, Gatherer n’a qu’une seule méthode abstraite :
Integrator<A, T, R> integrator();
L’élément Integrator est une interface fonctionnelle qui possède la méthode abstraite suivante :
boolean integrate(A state, T element, Downstream<? super R> downstream);
Le paramètre element représente l’élément de l’upstream, tandis que le paramètre downstream, comme son nom l’indique, modélise le downstream retourné par la méthode Gatherer.gather().
Exemple simple :
Gatherer<String, ?, String> gatherer = Gatherer.of((_, element, downstream) -> downstream.push(element) );
Ici, on pousse simplement tous les éléments de l’upstream dans le downstream.
Gestion du flux avec le booléen de retour
Comme vu dans la signature de la méthode integrate de l’interface Integrator, push() retourne un booléen.
Ce booléen indique si le downstream accepte ou non d’autres éléments. Lorsque false est retourné par la méthode integrate(), les prochains éléments de l’upstream vont être ignorés.
Il est recommandé par défaut de retourner true dans un élément Integrator, car on veut souvent traiter tous les éléments d’un stream (sauf si l’on veut utiliser limit() ou tout autre traitement spécifique).
Exemple pratique : Implémentation d’un filtre personnalisé
Prenons l’exemple d’un Gatherer qui filtre les éléments :
Gatherer<String, ?, String> filterGatherer = Gatherer.of((_, e, d) -> {
if (filter.test(e)) {
return d.push(e);
} else {
return true; // Continue le traitement même si l'élément n'est pas poussé
}
});
Dans cet exemple, j’ai utilisé une lambda pour créer un élément Integrator. Cependant, il existe des méthodes factory sur l’interface Integrator qui permettent de créer des Integrators de manière plus structurée :
Gatherer<String, ?, String> filterGatherer = Gatherer.of(
Integrator.of((_, e, d) -> {
if (filter.test(e)) {
return d.push(e);
} else {
return true; // Continue le traitement même si l'élément n'est pas poussé
}
})
);
Cette approche est strictement équivalente à l’utilisation directe de la lambda et n’apporte pas d’avantage particulier. Cependant, on peut créer un élément Integrator greedy (glouton) avec la méthode ofGreedy() :
Gatherer<String, ?, String> greedyFilterGatherer = Gatherer.of(
Integrator.ofGreedy((_, element, d) -> {
if (filter.test(element)) {
return d.push(element);
}
return true; // Continue toujours le traitement
})
);
Nuance importante sur les Integrators Greedy
La méthode ofGreedy() ne crée pas un élément Integrator qui ne peut jamais retourner false. La distinction est plus subtile : un Integrator greedy (glouton) traite tous les éléments qu’il peut et ne s’arrête que si le downstream lui indique qu’il ne peut plus accepter d’éléments.
Voici un exemple concret tiré de la JEP 485 :
<T> Gatherer<T, ?, T> nCopies(int n) {
return Gatherer.<T, T>of(
Gatherer.Integrator.ofGreedy((_, e, downstream) -> {
for (int i = 0; i < n; i++) {
if (!downstream.push(e)) return false; // Réaction au downstream
}
return !downstream.isRejecting(); // Réaction au downstream
}));
}
Dans cet exemple, l’élément Integrator greedy retourne false uniquement en réaction aux signaux du downstream (!downstream.push(element) ou downstream.isRejecting()). Il ne décide pas arbitrairement d’arrêter selon sa propre logique métier.
La différence clé :
Integrator classique : peut décider d’arrêter selon sa propre logique métier
Integrator greedy : ne s’arrête que si le downstream le force à s’arrêter
Gestion du state (état) dans les Gatherers
Jusqu’à présent, nous avons utilisé le paramètre state avec _ (underscore) pour l’ignorer. Cependant, le deuxième paramètre générique A de l’interface Gatherer<T, A, R> représente le type de l’état (state) que peut maintenir le Gatherer tout au long du traitement.
Le state permet aux Gatherers de conserver des informations entre les appels à la méthode integrate(). Cela est particulièrement utile pour des opérations d’agrégation ou de transformation qui nécessitent une mémoire du traitement précédent.
Initialisation du state
Pour utiliser un state, il faut définir un initializer qui crée l’état initial :
Gatherer<String, StringBuilder, String> gatherer = Gatherer.of(
() -> new StringBuilder(), // Initializer - crée le state initial
(state, e, downstream) -> { // Integrator element
state.append(e).append(" ");
return true;
}
);
Exemple pratique : Compteur d’éléments
Voici un exemple qui compte les éléments traités :
Gatherer<String, AtomicInteger, String> counterGatherer = Gatherer.of(
() -> new AtomicInteger(0), // State initial
(counter, e, downstream) -> {
int count = counter.incrementAndGet();
return downstream.push(e + " (" + count + ")");
}
);
// Utilisation
Stream.of("a", "b", "c")
.gather(counterGatherer)
.forEach(System.out::println);
// Sortie : a (1), b (2), c (3)
Note sur les performances : L’usage d’AtomicInteger dans cet exemple n’est pas optimal car la synchronisation n’est pas nécessaire dans le contexte d’un Gatherer (un seul thread traite les éléments). Il est préférable d’utiliser une classe simple :
class Counter {
int count = 0;
int increment() { return ++count; }
}
Gatherer<String, Counter, String> betterCounterGatherer = Gatherer.of(
Counter::new,
(counter, element, d) -> {
int count = counter.increment();
return d.push(element + " (" + count + ")");
}
);
Ou encore plus simplement avec une classe anonyme :
Gatherer<String, Object, String> simpleCounterGatherer = Gatherer.of(
() -> new Object() { int count = 0; },
(state, e, d) -> {
int count = ++((Object) { int count = 0; }) state).count;
return d.push(e + " (" + count + ")");
}
);
Finalisation avec un Finisher
Function<A, R> finisher()
https://openjdk.org/jeps/485
Transforms the final result container into the result
Un Stream Gatherer peut également définir un finisher qui est appelé à la fin du traitement pour traiter l’état final :
Gatherer<String, StringBuilder, String> concatenator = Gatherer.of(
() -> new StringBuilder(),
(state, element, downstream) -> {
state.append(element);
return true;
},
(state, downstream) -> { // Finisher
downstream.push(state.toString());
}
);Le finisher est particulièrement utile pour une opération d’agrégation qui ne produit un résultat qu’à la fin du traitement.
Finally, the finisher method is called once, with the combined state. It can push elements downstream. They are appended after any elements that are pushed in an integrator.
Gatherer.ofSequential
Parmi les implémentations prédéfinies les plus utiles des gatherers, on a la méthode ofSequential qui se distingue par sa capacité à traiter les éléments en préservant leur contexte séquentiel. Cette méthode factory crée un Gatherer qui maintient un état évolutif, permettant à chaque élément d’être transformé en tenant compte des éléments précédemment traités. L’état interne, initialisé via le supplier fourni, est progressivement modifié par l’integrateur à chaque étape, créant ainsi une chaîne de dépendances entre les éléments successifs. Cette approche s’avère indispensable pour des calculs de différences entre éléments consécutifs, l’accumulation progressive de valeurs, ou encore l’implémentation de filtres dépendants de l’historique. À la différence d’une opération parallélisable classique, ofSequential impose naturellement un traitement séquentiel, garantissant la cohérence des résultats lorsque l’ordre des éléments est critique pour la logique métier.
public static <T, R> Gatherer<T, ?, R> scan(
Supplier<R> initial,
BiFunction<? super R, ? super T, ? extends R> scanner) {
class State {
R current = initial.get();
}
return Gatherer.<T, State, R>ofSequential(
State::new,
Gatherer.Integrator.ofGreedy((state, element, d) -> {
state.current = scanner.apply(state.current, element);
return d.push(state.current);
})
);
}Exemple concret : Gestion de produits dans une codebase Java
Imaginons une application e-commerce avec des produits manipulés partout dans la code base Java. Voici comment les Gatherers peuvent améliorer la lisibilité et la ré-utilisabilité :
Avant : Code répétitif sans Gatherers
// Dans le service de commande
public List getAvailableProducts(List products) {
return products.stream()
.filter(Product::isAvailable)
.filter(p -> p.getStock() > 0)
.collect(toList());
}
// Dans le service de promotion
public List getPromotionalProducts(List products) {
return products.stream()
.filter(Product::isAvailable)
.filter(p -> p.getStock() > 0)
.filter(p -> p.getDiscount() > 0)
.collect(toList());
}
// Dans le service de catalogue
public List getTopProducts(List products, int limit) {
return products.stream()
.filter(Product::isAvailable)
.filter(p -> p.getStock() > 0)
.sorted((p1, p2) -> Double.compare(p2.getRating(), p1.getRating()))
.limit(limit)
.collect(toList());
}Après : Avec des Gatherers réutilisables
// Création de Gatherers métier réutilisables
public class ProductGatherers {
// Gatherer pour filtrer les produits vendables
public static final Gatherer<Product, ?, Product> sellable() {
return Gatherer.of(
Integrator.of((_, product, downstream) -> {
if (product.isAvailable() && product.getStock() > 0) {
return downstream.push(product);
}
return true;
})
);
}
// Gatherer pour enrichir avec des informations de stock
public static Gatherer<Product, ?, ProductWithStockInfo> withStockInfo() {
return Gatherer.of(
Integrator.of((_, product, downstream) -> {
StockLevel level = product.getStock() > 10 ? StockLevel.HIGH :
product.getStock() > 0 ? StockLevel.LOW : StockLevel.OUT;
return downstream.push(new ProductWithStockInfo(product, level));
})
);
}
// Gatherer pour grouper par catégorie avec limite
public static Gatherer<Product, ?, Product> limitPerCategory(int maxPerCategory) {
return Gatherer.of(
() -> new HashMap<String, Integer>(), // State: compteur par catégorie
(counters, product, downstream) -> {
String category = product.getCategory();
int currentCount = counters.getOrDefault(category, 0);
if (currentCount < maxPerCategory) {
counters.put(category, currentCount + 1);
return downstream.push(product);
}
return true; // Continue même si on n'ajoute pas le produit
}
);
}
}Utilisation dans les services
// Service de commande - code plus expressif
public List<Product> getAvailableProducts(List<Product> products) {
return products.stream()
.gather(ProductGatherers.sellable())
.toList();
}
// Service de promotion - composition claire
public List<ProductWithStockInfo> getPromotionalProducts(List<Product> products) {
return products.stream()
.gatһer(ProductGatherers.sellable())
.filter(p -> p.getDiscount() > 0)
.gather(ProductGatherers.withStockInfo())
.toList();
}
// Service de catalogue - logique métier claire
public List<Product> getTopProductsBalanced(List<Product> products, int maxPerCategory) {
return products.stream()
.gather(ProductGatherers.sellable())
.gather(ProductGatherers.limitPerCategory(maxPerCategory))
.sorted((p1, p2) -> Double.compare(p2.getRating(), p1.getRating()))
.toList();
}Avantages dans contexte Java avancé
Réutilisabilité : Le Gatherer sellable() est utilisé partout où on a besoin de produits vendables
Lisibilité : Le code exprime clairement l’intention métier
Maintenabilité : Un changement dans la logique « vendable » se fait en un seul endroit
Testabilité : Chaque Gatherer peut être testé indépendamment
Composition : Les Gatherers se combinent naturellement avec une opération Stream
Avantages des Stream Gatherer en général
Les éléments Stream Gatherer apportent plusieurs avantages significatifs aux projets Java :
Extensibilité : Possibilité de créer une opération intermédiaire personnalisée pour vos Stream.
Réutilisabilité : Les Gatherers peuvent être réutilisés dans différents contextes
Performance : Optimisations spécifiques possibles selon le cas d’usage
Expressivité : Code plus lisible et plus proche du domaine métier
Conclusion
Les éléments Stream Gatherer représentent un élément d’évolution naturel des Stream en Java, comblant un manque important dans l’écosystème Java. L’API offre aux développeurs la flexibilité nécessaire pour créer des opérations de traitement de données sur mesure, tout en conservant la philosophie et la performance des Streams.
Avec Java 25 LTS, cette API sera disponible en version stable, permettant aux équipes de l’adopter en toute confiance pour leurs projets à long terme.